








The market for data labeling solutions and services is expected to reach $57.63 billion by 2030, growing at a compound annual rate of 20.3%, according to Grand View Research. Financial services are a key driver of this growth due to their heavy reliance on AI systems for fraud detection, risk assessment, and compliance.
AI systems overwhelmingly employed by companies across industries are only as good as the data used to train them.
A fraud detection model can only identify suspicious activity if it has been trained on accurately labeled examples. The same applies to credit risk, compliance monitoring, customer service automation, and other financial AI applications. Without high-quality labeled data, performance suffers.
This is crucial in fintech. McKinsey reports that fintech companies account for roughly 40% of its dataset but nearly 70% of AI initiatives. As adoption accelerates, the demand for reliable data labeling continues to grow.
Choosing among the many data labeling providers is not easy. Financial organizations face additional requirements around fraud prevention, regulatory compliance, data privacy, and complex documentation. Those factors raise the bar well beyond standard annotation work.
This guide compares 13 leading providers based on the needs and realities of fintech and financial AI.
Top 13 Data Labeling Companies for Fintech and Financial AI in 2026: Comparison
| Company | Services | Global Presence | Employees | Year Est. |
|---|---|---|---|---|
| Helpware | Data labeling, LLM training and fine-tuning, data processing, AI model QA | USA, Mexico, Puerto Rico, Philippines, Ukraine, Georgia, Uganda, Germany, Poland, Albania (19 locations, 11 countries) | ~4,000 | 2015 |
| Scale AI | Data labeling, model training, GenAI data platform, RLHF | USA (HQ), global contractor network | ~1,200 | 2016 |
| Appen | Data annotation, data collection, RLHF, model evaluation | Australia (HQ), USA, plus crowd across 170+ countries | ~1,000 | 1996 |
| iMerit | Data annotation, model fine-tuning, validation, financial data labeling | USA (HQ), India, Bhutan, Europe | ~5,000 | 2012 |
| TELUS Digital | Data annotation, content moderation, GenAI data services | Canada (parent HQ), USA (AI data), 35+ countries | ~80,000 | 2005 |
| Sama | Data annotation, validation, model evaluation, computer vision and GenAI | USA (HQ), Kenya, Uganda, India | ~3,040 | 2008 |
| CloudFactory | Managed data labeling, GenAI data, RLHF | USA (HQ), Nepal, Kenya, UK | ~7,000 | 2010 |
| Labelbox | Data labeling platform, expert workforce, RLHF, model evaluation | USA (HQ), North America, Europe, Asia | ~200 | 2018 |
| SuperAnnotate | Annotation platform, LLM Data Engine, RLHF, model evaluation | USA (HQ), Europe, North America, Asia | ~305 | 2018 |
| Snorkel AI | Programmatic labeling, data development platform, financial document AI | USA (Redwood City) | ~776 | 2019 |
| Innodata | AI data preparation, annotation, model evaluation, AI safety testing | USA (HQ), India, Philippines, Canada | ~6,000 | 1988 |
| Cogito Tech | Enterprise data labeling, RLHF, fine-tuning, red teaming | USA (HQ), India, global innovation hubs | ~870 | 2014 |
| Surge AI | RLHF, RL environments, language data annotation, LLM training | USA (HQ), global expert community | ~130 | 2020 |
#1 Helpware
Compliance-focused annotation powered by dedicated specialists
Founded in 2015 and headquartered in Lexington, Kentucky, Helpware takes a managed workforce approach to data labeling. Instead of relying primarily on gig workers, the company uses trained, full-time specialists supported by automation and quality-control systems.
Its AI data annotation and LLM training services are part of a broader data operations offering. For financial organizations, Helpware labels transactions, documents, and audio data used in fraud detection, process automation, and other AI-driven workflows. In these operations, accuracy and judgment matter as much as speed.
Helpware operates across 19 locations in 11 countries and supports more than 45 languages through native-speaking teams. Its banking and financial services practice covers a range of regulated workflows, including loan processing and customer operations. The company maintains compliance with standards such as SOC 2, HIPAA, GDPR, and PCI DSS.
According to Helpware, its human-in-the-loop approach delivers 35% faster data processing, 30% fewer labeling errors, and 45% stronger bias detection.
Why we picked it
Helpware ranks first because it combines compliance expertise, experienced reviewers, and operational stability. Client relationships average more than five years, monthly employee attrition is just 2.8%, and its financial-sector experience includes work with crypto exchange Bittrex Global.
- Services offered: Data labeling and annotation across text, image, video, and audio, data collection, cleansing, and categorization, LLM training and fine-tuning, human-in-the-loop review, synthetic data generation, AI model testing and quality assurance.
- Pros: Vetted full-time annotators instead of crowdsourcing, native-speaker coverage in 45+ languages, 90% CSAT and 2.8% attrition, SOC 2, HIPAA, GDPR, and PCI DSS compliance, fintech reviewers for fraud and document tasks.
- Cons: Premium pricing compared to offshore commodity labelers, consultative onboarding that takes longer than a self-serve tool.
- Industry expertise: Fintech and banking, healthcare, SaaS and software, ecommerce and retail, gaming, public sector, automotive and logistics.
- Best for: Mid-market to enterprise fintech and financial AI teams that need compliant, domain-aware labeling with long-term continuity.
- Pricing: Starting at $8 to $15 per hour depending on complexity, location, and engagement model.
- Year established: 2015
- Location: Lexington, Kentucky (HQ), with 19 locations across the USA, Mexico, Puerto Rico, the Philippines, Ukraine, Georgia, Uganda, Germany, Poland, and Albania.
#2 Scale AI

Enterprise data engine powering frontier labs and government programs
Founded in 2016 by Alexandr Wang and Lucy Guo, Scale AI has become one of the most recognized names in AI training data. Headquartered in San Francisco, the company serves technology businesses, government agencies, automotive organizations, and financial institutions.
Its platforms, including Scale Rapid and Scale GenAI, use consensus-based workflows in which multiple annotators review the same data. Differences are flagged and resolved to improve quality and consistency.
In June 2025, Meta acquired a 49% stake in the company for $14.3 billion. Following the investment, several major customers reduced their engagements, and Scale shifted more attention toward enterprise and government programs.
Why we picked it
Scale AI stands out for its sophisticated tooling, automation capabilities, and experience managing large, complex data programs. Financial institutions with significant labeling requirements and enterprise-scale AI initiatives may find it particularly well suited to their needs.
- Services offered: Data labeling, model training data, GenAI data platform, RLHF, model evaluation.
- Pros: Proprietary automation infrastructure, consensus-based quality control, deep experience with frontier and enterprise AI.
- Cons: Customer concerns following Meta’s stake, high minimum engagements that rarely suit startups or mid-market teams.
- Industry expertise: Technology, government and defense, automotive, finance, ecommerce.
- Best for: Large enterprises and AI labs with substantial, well-funded labeling programs.
- Pricing: Custom, based on volume and complexity.
- Year established: 2016
- Location: San Francisco, California, with a global contractor network.
#3 Appen
Global language expertise backed by decades of experience
Appen has been providing training data services since 1996, making it one of the longest-established companies in the industry. Headquartered in Sydney and publicly traded on the Australian Securities Exchange, the company also maintains a major presence in the United States.
Its AI-assisted annotation platform is supported by a crowd workforce of about 1,000 in-house employees and more than one million freelance contributors across over 170 countries, covering more than 235 languages and dialects.
Appen’s services include supervised fine-tuning, reinforcement learning from human feedback (RLHF), model evaluation, and data annotation for industries such as technology, automotive, retail, healthcare, government, and financial services.
Why we picked it
Appen’s greatest strength is scale. Few competitors can match its global language coverage or operational experience. The trade-off is that quality can vary within large crowd-based workforce, and the company has faced business challenges in recent years.
- Services offered: Data annotation, data collection, RLHF, supervised fine-tuning, model evaluation, speech data.
- Pros: Crowd of over one million contributors, 235-plus languages, AI-assisted platform with smart and pre-labeling, long enterprise track record.
- Cons: Crowdsourced quality can be uneven, recent financial headwinds.
- Industry expertise: Technology, automotive, financial services, retail, healthcare, government.
- Best for: Teams that need very large, multilingual datasets and speech data at scale.
- Pricing: Custom, from self-serve to white-glove managed service.
- Year established: 1996
- Location: Sydney, Australia headquarters and a US base in Kirkland, Washington, with global offices.
#4 iMerit

Domain-expert annotation for regulated, high-stakes finance data
Founded in 2012 by Radha Basu and headquartered in San Jose, iMerit focuses on trained, full-time annotation teams instead of crowd labor. The company operates across India, the United States, Bhutan, and Europe.
Its financial services teams support banks, payment providers, credit bureaus, and expense management platforms. Their work includes labeling transactions, extracting information from documents, and organizing unstructured text and visual data used for fraud detection, compliance, and operational automation.
Beyond annotation, iMerit also provides RLHF, red teaming, and validation services for generative AI systems.
Why we picked it
iMerit excels in projects where accuracy carries significant business or regulatory consequences. Its subject-matter expertise and full-time workforce model make it a strong choice for financial organizations that want experienced reviewers handling sensitive data.
- Services offered: Data annotation for computer vision, NLP, audio, and LiDAR, model fine-tuning, validation, RLHF, financial document labeling.
- Pros: Full-time domain experts, dedicated finance practice, strong fit for fraud and document workflows.
- Cons: Project-based delivery, smaller language footprint than crowd vendors.
- Industry expertise: Financial services, medical AI, autonomous mobility, geospatial, commerce, government.
- Best for: Banks and fintechs labeling complex financial documents and transactions under compliance pressure.
- Pricing: Custom, based on project scope.
- Year established: 2012
- Location: San Jose, California headquarters, with teams in India, Bhutan, and Europe.
#5 TELUS Digital (AI Data Solutions)
Enterprise-scale annotation backed by a global services organization
TELUS Digital, the technology and outsourcing arm of TELUS Corporation, was founded in 2005 and is publicly traded under the ticker TIXT. Its AI Data Solutions division was built through the acquisitions of Lionbridge AI and Playment.
Today, the business works with an AI community of more than one million contributors across more than 500 languages and delivers over two billion labels annually.
The company has been recognized as a Leader in Everest Group’s Data Annotation and Labeling assessment and serves clients across ecommerce, fintech, healthcare, technology, and travel.
Why we picked it
TELUS Digital combines large-scale annotation capabilities with the operational maturity of a publicly traded enterprise. For financial institutions that place a premium on vendor stability, governance, and quality controls, that combination can be particularly attractive.
- Services offered: Data annotation, content moderation, trust and safety, GenAI data services, intelligent automation.
- Pros: Million-plus annotator community, 500-plus languages, two billion-plus labels a year, public-company stability.
- Cons: Large-vendor processes, less boutique attention than specialist shops.
- Industry expertise: Technology and games, ecommerce and fintech, healthcare, communications and media, travel.
- Best for: Enterprises that want annotation scale inside a stable, regulated BPO relationship.
- Pricing: Custom.
- Year established: 2005
- Location: Vancouver, Canada parent headquarters, with AI Data Solutions based in Las Vegas, Nevada.
#6 Sama

In-house annotation with a certified ethical workforce model
Founded in 2008 as Samasource by the late Leila Janah, Sama is headquartered in San Francisco and operates as a Certified B Corporation. Unlike many providers that rely on crowdsourced labor, Sama employs and manages its own workforce through delivery centers in Kenya, Uganda, and India.
The company built its reputation in computer vision and has since expanded into natural language processing and generative AI. Sama reports a 99% first-batch acceptance rate across its workforce of roughly 3,040 employees. Its client roster includes major global brands such as GM, Ford, Google, Nvidia, and Walmart.
Why we picked it
Sama stands out for combining strong quality standards with an ethical sourcing model. For some financial institutions, workforce practices and social impact have become important factors in vendor selection.
Its primary strength remains computer vision, however. Organizations looking for deep fintech expertise or extensive experience with financial datasets may find stronger specialization elsewhere on this list.
- Services offered: Data annotation, validation, model evaluation, computer vision and generative AI data.
- Pros: In-house expert teams, 99% first-batch acceptance, B-Corp ethical sourcing, integrated QA platform.
- Cons: Computer-vision heritage, thinner finance-specific specialization.
- Industry expertise: Automotive, retail and ecommerce, consumer and media, medtech, manufacturing, agriculture.
- Best for: Teams that prioritize annotation quality and an auditable, ethical supply chain.
- Pricing: Custom, based on project.
- Year established: 2008
- Location: San Francisco, California headquarters, with delivery centers in Kenya, Uganda, and India.
#7 CloudFactory
Dedicated analyst teams for complex financial workflows
Founded in 2010 and headquartered in Durham, North Carolina, CloudFactory provides clients with dedicated teams of trained analysts instead of crowdsourced workers. Its workforce includes more than 7,000 analysts across Nepal, Kenya, the United Kingdom, and the United States.
The company emphasizes structured training, ongoing performance monitoring, and continuous skill development. Beyond traditional data labeling, CloudFactory offers services that support generative AI initiatives, including model tuning, prompt engineering, retrieval systems, and reinforcement learning from human feedback (RLHF).
Why we picked it
CloudFactory’s biggest advantage is accountability. Financial documents, lending workflows, and insurance claims often require consistency and attention to detail that are difficult to achieve with large crowdsourced networks. The company is particularly well suited for organizations that value dedicated teams and clearly defined processes. Potential limitations include less extensive support for non-English language projects and slower scaling during sudden spikes in demand.
- Services offered: Managed data labeling and annotation, data processing, GenAI data, RLHF, prompt engineering.
- Pros: Dedicated managed teams, strong quality assurance and documentation, decade-plus experience.
- Cons: Limited support for non-English NLP, scaling speed can vary for burst projects.
- Industry expertise: Finance, insurance, healthcare, retail, geospatial, autonomous vehicles.
- Best for: Finance and insurance teams that want a stable, trained team over a rotating crowd.
- Pricing: Managed monthly engagement.
- Year established: 2010
- Location: Durham, North Carolina headquarters, with operations in Nepal, Kenya, and the UK.
#8 Labelbox

Software-first data factory with an on-demand expert bench
Founded in 2018 by Manu Sharma, Brian Rieger, and Dan Rasmuson, Labelbox takes a software-first approach to data labeling. The platform allows organizations to manage their own annotation workflows while providing access to on-demand experts through its Boost service and Alignerr community.
Backed by investors, Labelbox supports supervised fine-tuning, RLHF, and model evaluation. Its platform includes tools for annotation management, quality assurance, and integration with machine learning pipelines. The company works with Fortune 500 organizations and leading AI development teams.
Why we picked it
Labelbox is a strong option for financial institutions that want visibility and control over the labeling process. The platform provides clear audit trails, workflow management, and integration with existing AI infrastructure.
Organizations seeking a fully managed service should be aware that Labelbox is primarily a software platform. In many cases, clients are responsible for providing or sourcing the annotation workforce.
- Services offered: Data labeling platform, on-demand expert labeling, RLHF, supervised fine-tuning, model evaluation.
- Pros: Software-first control and transparency, strong ML pipeline integrations, expert community on demand.
- Cons: Platform-centric, so it needs internal or contracted annotators for fully managed work.
- Industry expertise: Technology, enterprise AI, research, with cross-industry use including finance.
- Best for: In-house AI teams that want to own and audit their labeling workflows.
- Pricing: Tiered subscription by data volume, users, and features.
- Year established: 2018
- Location: San Francisco, California headquarters, with presence across North America, Europe, and Asia.
#9 SuperAnnotate
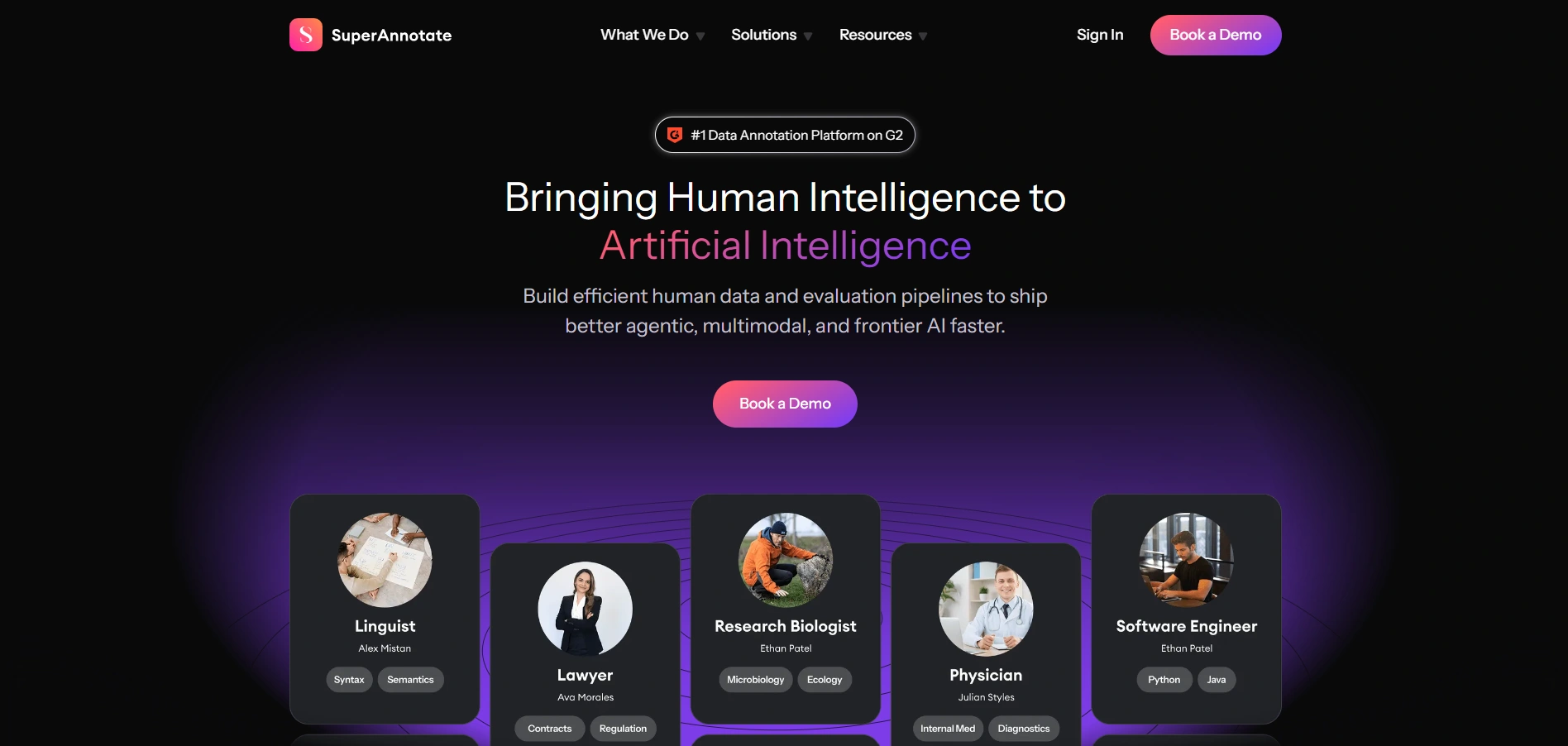
End-to-end platform plus a managed workforce for LLM data
Founded in 2018 and headquartered in San Francisco, SuperAnnotate offers a unified platform for dataset creation, annotation, curation, and model evaluation. The company also provides access to a professionally managed annotation workforce. Its LLM Data Engine helps organizations build, fine-tune, and evaluate large language models, supported by tools for RLHF, quality assurance, and data curation. The company has approximately 305 employees and is backed by investors including NVIDIA, Databricks, and Dell Technologies Capital. Customers include Databricks and ServiceNow.
Why we picked it
SuperAnnotate earns its place for its comprehensive tooling and strong support for LLM development. The platform helps AI teams move quickly while maintaining quality standards throughout the model development process. The tradeoff is a learning curve on the platform, and finance is not yet its headline vertical, so domain expertise may need to come from your side.
- Services offered: Annotation platform, LLM Data Engine, RLHF, data curation, model evaluation, managed workforce marketplace.
- Pros: Unified tooling with QA and automation, strong LLM and generative AI support, vetted managed workforce.
- Cons: Platform learning curve, finance not a primary vertical.
- Industry expertise: Technology, healthcare, autonomous driving, security, enterprise AI.
- Best for: ML teams building and evaluating LLMs that want one platform end to end.
- Pricing: Custom subscription.
- Year established: 2018
- Location: San Francisco, California headquarters, with presence across Europe, North America, and Asia.
#10 Snorkel AI
Programmatic labeling trusted by top US banks
Founded in 2019 as a spinout from the Stanford AI Lab, Snorkel AI is headquartered in Redwood City and focuses on programmatic data labeling. Instead of hand-labeling every record, subject-matter experts write functions that encode their rules, which Snorkel Flow then uses to label and manage data at scale.
What sets it apart for finance is exactly this approach: seven of the top US banks use Snorkel to extract information from complex financial documents, and clients such as BNY and Chubb sit alongside Wayfair across its roughly 776-person team.
Why we picked it
Snorkel is particularly well suited to the messiest corner of financial AI, the private, fast-changing documents where requirements shift and manual relabeling never ends. However, Snorkel is a data development platform, not a managed annotation provider. Teams need technical expertise to build and maintain labeling functions and workflows to get the most value from it.
- Services offered: Programmatic data labeling, data development platform, dataset curation, model evaluation, expert dataset services.
- Pros: Programmatic approach suits private and changing data, deep financial-document track record, fast relabeling.
- Cons: Learning curve for weak supervision, not a hands-on annotation workforce.
- Industry expertise: Banking and finance, insurance, healthcare, public sector.
- Best for: Banks and fintechs extracting structure from proprietary, frequently changing documents.
- Pricing: Enterprise, custom.
- Year established: 2019
- Location: Redwood City, California.
#11 Innodata
A long-established data engineering partner with compliance expertise
Founded in 1988 and headquartered in Ridgefield Park, New Jersey, Innodata brings more than three decades of data engineering experience to the AI market. Publicly traded on Nasdaq under the ticker INOD, the company provides AI data preparation, annotation, model evaluation, and AI safety testing through its Digital Data Solutions business.
Innodata employs more than 6,000 people across India, the Philippines, and Canada, and serves large enterprises developing and deploying AI systems. Its broader business also includes financial compliance and media intelligence services, giving it experience in regulated environments.
Why we picked it
Innodata earns a place on this list because of its longevity, operational scale, and compliance-oriented approach. For financial institutions looking for an established public company with a long track record, those qualities can be appealing. The flip side is a legacy BPO feel, and it can read as less LLM-native than the newer, venture-backed names on this list.
- Services offered: AI data preparation and annotation, model evaluation, AI safety testing, data transformation and compliance.
- Pros: Three-decade track record, public-company governance, financial-compliance expertise.
- Cons: Legacy BPO orientation, less LLM-native positioning than newer rivals.
- Industry expertise: Financial services and compliance, technology, healthcare, media, government.
- Best for: Enterprises that want an established, publicly accountable data-engineering partner.
- Pricing: Custom.
- Year established: 1988
- Location: Ridgefield Park, New Jersey headquarters, with operations in India, the Philippines, and Canada.
#12 Cogito Tech
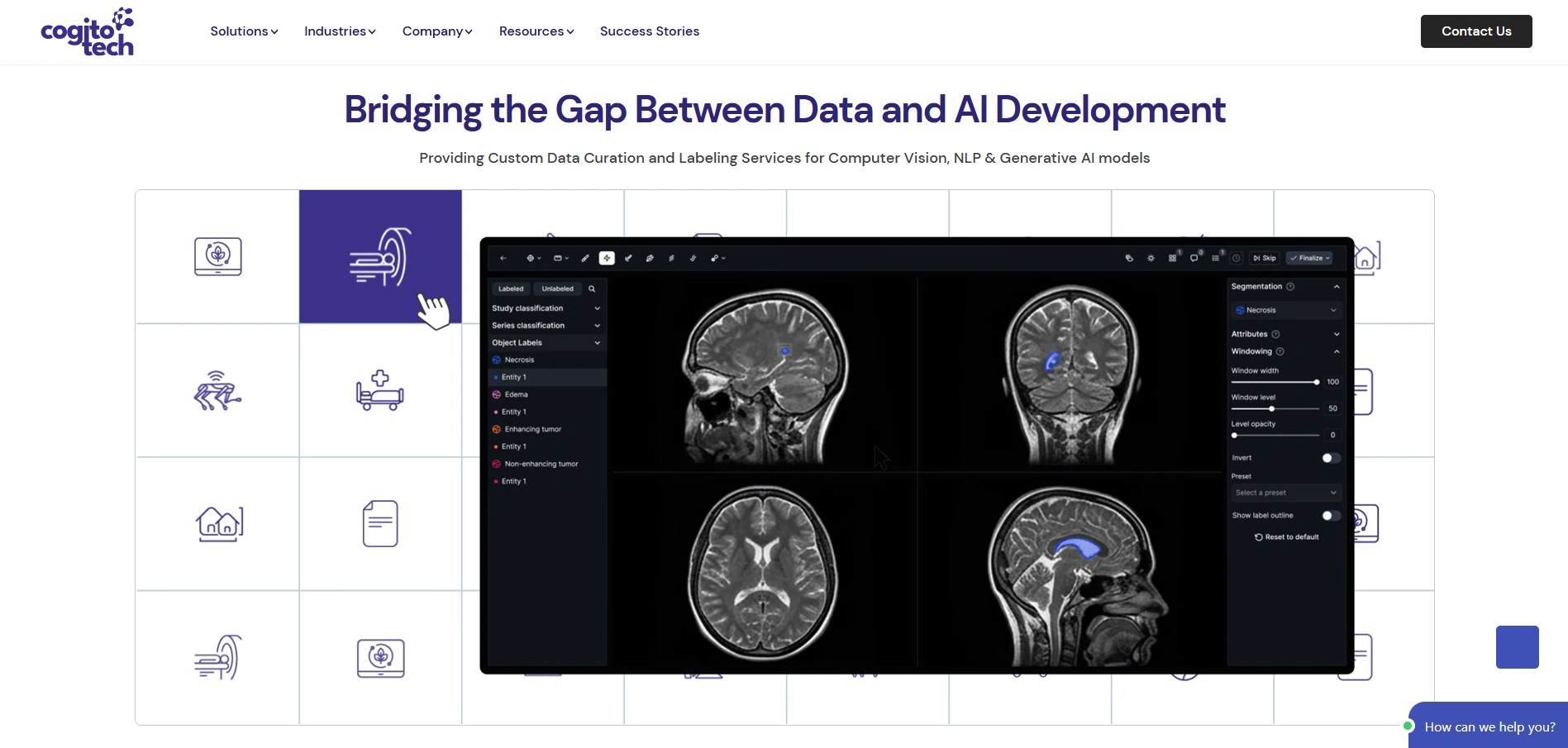
Compliance-certified labeling with transparent data origin
Founded in 2014 and headquartered in Levittown, New York, with delivery in India, Cogito Tech runs a full-time annotation workforce of roughly 870 across innovation hubs in Europe, Asia-Pacific, Latin America, and North America. Its Enterprise Data Labeling Services cover RLHF, fine-tuning, red teaming, and prompt engineering, and it certifies work against GDPR, SOC 2 Type II, HIPAA, ISO 27001, and ISO 9001. Its DataSum framework provides a clear record of how training data was collected and prepared.
Why we picked it
Cogito makes the cut on certifications and data sourcing, which matter when a regulator or auditor asks where financial training data came from.
The main limitation is scale. While highly capable, Cogito operates on a smaller footprint than some of the largest providers on this list.
- Services offered: Enterprise data labeling and annotation, RLHF, fine-tuning, red teaming, prompt engineering, data curation.
- Pros: Broad compliance certifications, transparent data sourcing, trained workforce.
- Cons: Smaller scale than the largest providers, less brand recognition.
- Industry expertise: Finance, healthcare, automotive, agriculture, defense.
- Best for: Regulated finance teams that need certified, auditable labeling with clear origin.
- Pricing: Custom.
- Year established: 2014
- Location: Levittown, New York headquarters, with delivery in India and global innovation hubs.
#13 Surge AI
High-end annotation for advanced AI models
Founded in 2020 by Edwin Chen and headquartered in San Francisco, Surge AI specializes in RLHF, reinforcement learning environments, and high-quality language data for advanced AI systems. The company focuses on expertise over volume. Its network includes roughly 50,000 carefully screened contributors supported by about 130 full-time employees. Surge works with some of the most prominent names in AI, including OpenAI, Anthropic, Microsoft, Meta, and Google.
The company was profitable before raising outside funding for the first time in 2025, an uncommon achievement in the AI sector.
Why we picked it
Surge AI is known for the quality of its language annotation work. For financial AI applications that depend on nuanced reasoning, contextual understanding, and complex decision-making, that expertise can be valuable. However, Surge typically operates at a premium price point, and its focus on frontier AI development may make it more than many mid-market fintech organizations require.
- Services offered: RLHF, reinforcement-learning environments, language data annotation, LLM training data, model evaluation and red teaming.
- Pros: Highly vetted annotators, strong fit for reasoning-heavy and safety-critical data, high reported accuracy.
- Cons: Premium pricing, oriented to frontier labs more than everyday fintech operations.
- Industry expertise: Frontier AI labs, enterprise technology, with high-precision use across domains.
- Best for: Teams building reasoning-heavy or safety-critical financial AI that demand the highest data quality.
- Pricing: Premium, usage-based plus managed contracts.
- Year established: 2020
- Location: San Francisco, California, with a global expert community.
Helpware: Our Top Choice
Among the 13 providers reviewed, Helpware stands out because it approaches data labeling as expert work, not a volume exercise. While many competitors focus on crowdsourced scale or software platforms, Helpware relies on trained, full-time reviewers who understand financial documents, transaction data, fraud indicators, and compliance requirements.
Three factors set the company apart:
- Strong compliance coverage, including SOC 2, HIPAA, GDPR, and PCI DSS.
- A global operating footprint spanning 19 locations and more than 45 languages.
- Long-term client relationships, with partnerships averaging more than five years.
According to the company, its human-in-the-loop model also contributes to 35% faster processing times and 30% fewer labeling errors.
Helpware’s pricing is typically higher than commodity labeling providers, and onboarding can take longer than with self-service platforms. For organizations that view data quality, compliance, and model performance as strategic priorities, that trade-off may be worthwhile.
Choosing the Right Data Labeling Partner
The data labeling market is becoming more specialized. Some providers offer self-service software platforms. Others focus on crowdsourced workforces, programmatic labeling tools, or managed expert teams.
There is no single best model for every fintech organization. The right choice depends on how your AI systems are built, how sensitive your data is, and what the cost of a labeling mistake would be. A fraud detection model, for example, has very different requirements than a customer support chatbot.
Look beyond price per label. Evaluate data governance, compliance controls, workforce quality, and domain expertise. Ask how edge cases are reviewed, how quality is measured, and how training data is documented.
In financial services, the cheapest option is not always the least expensive in the long run.




